NumPy
- Numeric Python의 줄임말
- 수학/과학 연산을 위한 파이썬 패키지
- NumArray & Numeric 이라는 기존 파이썬 패키지를 계승함
- 행렬 및 벡터을 사용하는 선형 대수 계산과 다차원 배열을 다룰 때 사용됨
- 파이썬의 list와 거의 흡사하나 순수 파이썬에 비해 연산 속도가 빠름
배열(array)의 종류
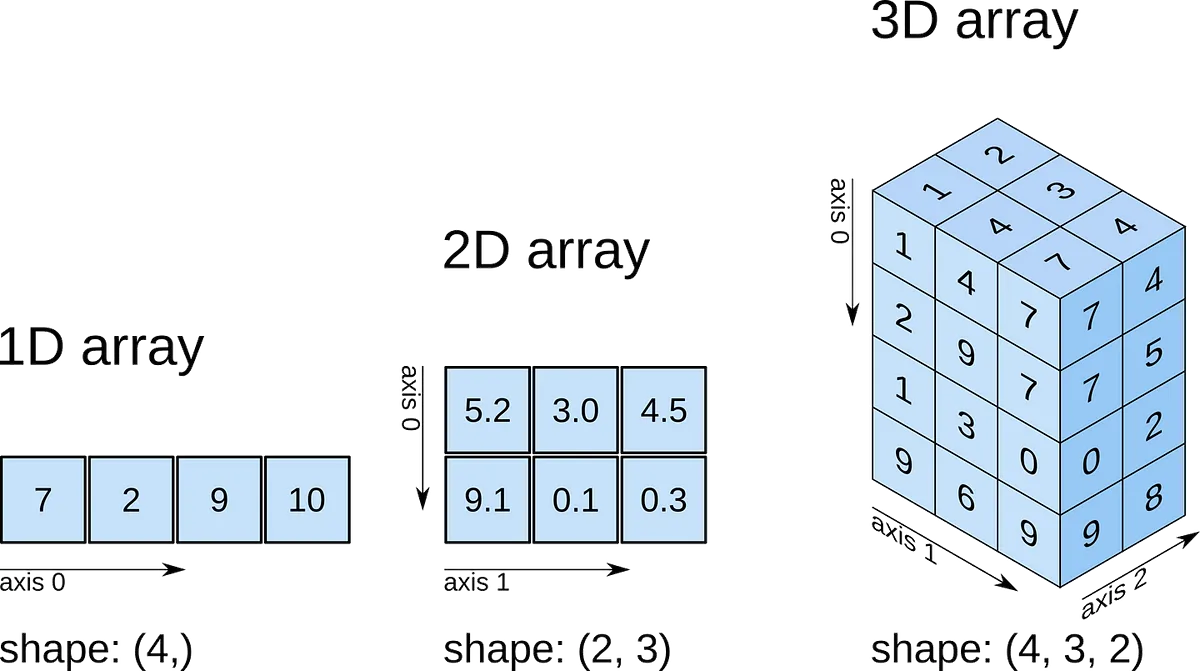
- NumPy의 자료형 : ndarray
- ndarray : nth dimensional array object (다차원 행렬 배열 객체)
- 1차원 배열 : Vector (axis(축)=0 : 행)
- 2차원 배열 : Matrix, (axis=1 : 열)
- 3차원 배열 : Tensor, (axis=2 : 채널)
- ndarray의 특징 : list와 다르게 서로 다른 데이터 타입의 요소를 담을 수 없음
NumPy 기본 함수
생성 함수
array() : 배열 생성 (기존 데이터를 NumPy 배열로 변환)
import numpy as np
# 리스트를 NumPy 배열로 변환
list_data = [1, 2, 3, 4, 5]
arr = np.array(list_data)
print(arr) # 출력: [1 2 3 4 5]
# 다차원 리스트를 2차원 배열로 변환
nested_list = [[1, 2, 3], [4, 5, 6]]
arr_2d = np.array(nested_list)
print(arr_2d)
# [[1 2 3]
# [4 5 6]]
배열에 실수형 데이터가 한개라도 있으면 전체 데이터가 실수형으로 분류됨
b = np.array([3.14, 4, 2, 3])
b
# array([3.14, 4. , 2. , 3. ])
배열 내 데이터형 지정 가능
c = np.array([1, 2, 3, 4], dtype = float)
c
# array([1., 2., 3., 4.])
zeros() : a개의 행이 있는 배열 내 각각 특정 데이터 종류의 값이 0인 데이터를 생성
- 머신러닝의 기본 틀로 자주 사용됨
np.zeros(3, 'int64')
# array([0, 0, 0])
np.zeros((4,5),'str')
# array([['', '', '', '', ''],
# ['', '', '', '', ''],
# ['', '', '', '', ''],
# ['', '', '', '', '']], dtype='<U1')
ones() : a개의 행이 있는 배열 내 각각 특정 데이터 종류의 값이 1인 데이터를 생성
np.ones((7,4),'bool')
# array([[ True, True, True, True],
# [ True, True, True, True],
# [ True, True, True, True],
# [ True, True, True, True],
# [ True, True, True, True],
# [ True, True, True, True],
# [ True, True, True, True]])
arange() : 0 부터 n개의 정수(int) 생성
np.arange(6)
# array([0, 1, 2, 3, 4, 5])
linspace() : 지정한 구간 내 균등한 간격으로 나눈 값을 가진 배열 생성
np.linspace(0, 1, 5)
# array([0. , 0.25, 0.5 , 0.75, 1. ])
random.rand() : 0과 1 사이의 난수 배열 생성
np.random.rand(2, 2)
# array([[0.34427996, 0.81540163],
# [0.50520938, 0.34506994]])
배열 속성값 확인
ndim() : 배열의 차원 수 반환
arr1 = np.array([1, 2, 3]) # 1차원 배열
arr2 = np.array([[1, 2, 3], [4, 5, 6]]) # 2차원 배열
print(arr1.ndim) # 출력: 1
print(arr2.ndim) # 출력: 2
shape() : 배열의 각 차원의 크기 반환
arr = np.array([[1, 2, 3], [4, 5, 6]]) # 2x3 배열
print(arr.shape) # 출력: (2, 3)
dtype() : 데이터 타입 반환
arr = np.array([1.5, 2.3, 3.7])
print(arr.dtype) # 출력: float64
reshape() - 배열 수정 (차원과 크기 변경)
a = np.arange(6).reshape((3,2)) # 3행 2열로 변경
a
# array([[0, 1],
# [2, 3],
# [4, 5]])Pandas
- PANel Data Analysis의 줄임말
- 데이터 조작 및 분석을 위한 NumPy 기반 파이썬 패키지
- 본래 금융 데이터 분석을 위해 만들어짐
- DataFrame 자료형 제공
- DataFrame : 행과 열이 있는 테이블 형태의 데이터
- Pandas의 주 기능 : CRUD (Create, Read, Update, Delete)
- 엑셀보다 대용량의 데이터를 더 빠르게 다룰 수 있음
Pandas 구성
- Series : 1차원 데이터 셋 - 데이터(1개의 컬럼 값)와 인덱스로 구성
- DataFrame : 2차원 데이터 셋 - 컬럼, 데이터와 인덱스로 구성
- 인덱스(index) : 각 데이터의 고유한 키 값 (unique ID)
import pandas as pd
# Series 생성
s = pd.Series([1, 3, 5, 7, 9])
# DataFrame 생성
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
Pandas 기본 함수
데이터 가져오기 및 저장하기
df = pd.read_csv('data.csv') # CSV 파일을 읽어 DataFrame으로 변환
df.to_csv('output.csv', index=False) # DataFrame을 CSV 파일로 저장
데이터 탐색 및 요약
df.head() # 데이터의 첫 n개 행 출력 (기본값: 5)
df.tail() # 데이터의 마지막 n개 행 출력 (기본값: 5)
df.info() # 데이터프레임의 요약 정보 출력 (열의 이름, 데이터 타입, 결측값 정보 등)
df.describe() # 수치형 데이터의 통계 요약 출력 (평균, 표준편차, 최소값, 최대값 등)
df.shape # 데이터프레임의 행과 열의 크기 확인
df.columns # 데이터프레임의 열 이름 확인
df.index # 데이터프레임의 인덱스 확인데이터 선택 및 필터링
df['name'] # 'name'이라는 이름의 열 선택
df.loc[0] # 첫 번째 행 선택 (인덱스 레이블 기반)
df.iloc[2] # 세 번째 행 선택 (정수 인덱스 기반)
df_sorted = df.sort_values(by='A', ascending=False) # 'A' 열 기준 내림차순 정렬
df_sorted = df.sort_index(ascending=True) # 인덱스 기준 오름차순 정렬데이터프레임 수정
df['D'] = [10, 11, 12] # 열 추가
df.loc[0, 'A'] = 100 # 첫 번째 행, 'A' 열의 값을 100으로 수정
df.fillna(0) # 결측값을 0으로 채움
df.dropna() # 결측값이 있는 행을 삭제
grouped = df.groupby('A')
print(grouped.mean()) # 그룹별 평균 계산
df.agg(['mean', 'sum']) # 평균과 합계를 동시에 계산데이터 합치기
merged_df = pd.merge(df1, df2, on='key_column')
concatenated_df = pd.concat([df1, df2], axis=0) # 행 기준으로 연결고유값 및 값 계산
unique_values = df['A'].unique() # 특정 열에서 중복되지 않은 고유값을 반환
value_counts = df['A'].value_counts() # 특정 열에서 값의 개수를 세어 반환피벗 테이블 생성
pivot = df.pivot_table(values='C', index='A', columns='B', aggfunc='sum')MatPlotLib
- 파이썬에서 가장 널리 사용되는 2D 그래프 및 시각화 라이브러리
- pyplot 모듈을 통해 간단한 플롯을 그릴 수 있음
선 그래프 (line plot)
import matplotlib.pyplot as plt
x = [1, 2, 3, 4]
y = [1, 4, 9, 16]
plt.plot(x, y) # 기본적인 선 그래프를 그릴 때 사용
plt.show() # 그래프를 화면에 출력
산점도 (scatter plot)
x = [1, 2, 3, 4]
y = [10, 20, 25, 30]
plt.scatter(x, y) # 점들을 사용하여 데이터 분포를 나타내는 산점도를 그림
plt.show()
그래프 요소 추가
x = [1, 2, 3, 4]
y1 = [1, 4, 9, 16]
y2 = [2, 4, 6, 8]
plt.plot(x, y1, label='Quadratic')
plt.plot(x, y2, label='Linear')
plt.title('Example Plot') # 그래프 제목 추가
plt.xlabel('X Axis') # x축 레이블 추가
plt.ylabel('Y Axis') # y축 레이블 추가
plt.legend() # 범례 추가
plt.grid(True) # 격자 추가
plt.show()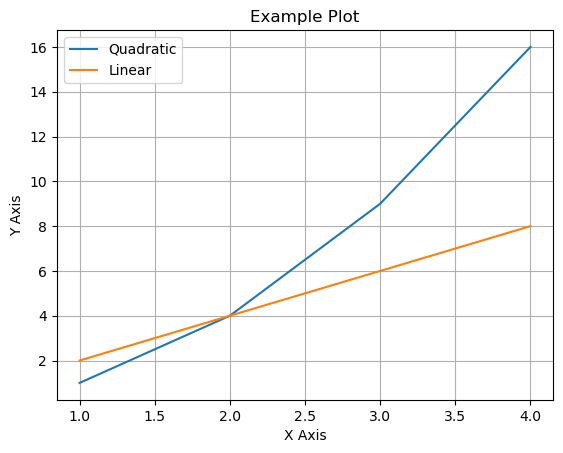
그래프 스타일 지정
plt.plot(x, y1, color='blue', linestyle='--', marker='o', label='Dashed Line with Circles')
plt.plot(x, y2, color='red', linestyle='-', marker='x', label='Solid Line with X')
# color: 선의 색상 (예: 'blue', 'red')
# linestyle: 선 스타일 (예: '-'(실선), '--'(대시))
# marker: 데이터 포인트에 마커를 추가 (예: 'o', 'x', '^')
plt.legend()
plt.show()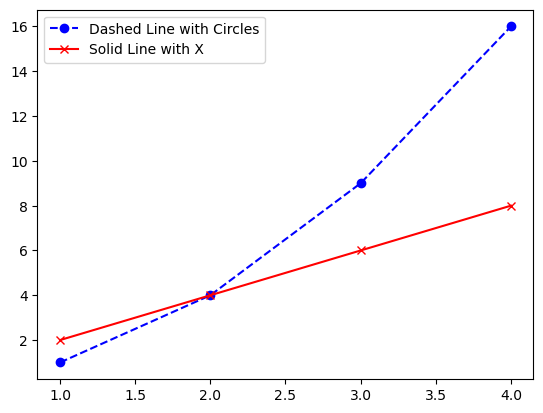
여러 그래프 그리기
plt.subplot(1, 2, 1) # 1행 2열에서 첫 번째 그래프
plt.plot(x, y1)
plt.title('First Plot')
plt.subplot(1, 2, 2) # 1행 2열에서 두 번째 그래프
plt.plot(x, y2)
plt.title('Second Plot')
plt.show()
막대 그래프 (bar plot)
categories = ['A', 'B', 'C', 'D']
values = [10, 20, 15, 30]
plt.bar(categories, values)
plt.title('Bar Plot')
plt.show()
히스토그램 (histogram)
data = [1, 1, 2, 2, 2, 3, 3, 4, 4, 4, 4, 5, 5]
plt.hist(data, bins=5) # 5개의 구간으로 나누어 히스토그램 생성
plt.title('Histogram')
plt.show()
파이 차트 (pie chart)
sizes = [15, 30, 45, 10]
labels = ['A', 'B', 'C', 'D']
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue']
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%')
plt.title('Pie Chart')
plt.show()
박스 플롯 (box plot)
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
plt.boxplot(data, vert=True, patch_artist=True)
plt.title('Box Plot')
plt.show()
로그 스케일 (box plot)
# 그래프의 축을 로그 스케일로 변경하여, 데이터의 비율적 변화를 시각화
x = [1, 10, 100, 1000]
y = [1, 2, 3, 4]
plt.plot(x, y)
plt.xscale('log') # X축을 로그 스케일로 변경
plt.yscale('log') # Y축을 로그 스케일로 변경
plt.title('Logarithmic Scale Plot')
plt.show()
imshow() : 이미지나 행렬 데이터를 시각화
import numpy as np
data = np.random.random((10, 10)) # 10x10 랜덤 행렬
plt.imshow(data, cmap='hot', interpolation='nearest')
plt.colorbar() # 컬러바 추가
plt.title('Heatmap')
plt.show()
Seaborn
- Matplotlib 위에 구축된 고수준 데이터 시각화 라이브러리
- 통계적 그래프를 그릴 때 사용
- 데이터프레임과 잘 통합되어 데이터 분석을 위한 시각화를 쉽게 할 수 있음
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris # scikit-learn의 Iris 데이터셋 활용
import pandas as pd# Iris 데이터셋 로드
iris = load_iris()
# 데이터를 pandas 데이터프레임으로 변환
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['species'] = iris.target # 'species' 열 추가
iris_df['species'] = iris_df['species'].apply(lambda x: iris.target_names[x]) # 숫자를 실제 이름으로 변환
# 데이터 확인
print(iris_df.head())
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosaPair Plot
sns.pairplot(iris_df, hue='species') # 품종별로 색상을 구분하여 시각화
plt.show()
# 각 변수의 산점도와 히스토그램을 한 번에 시각화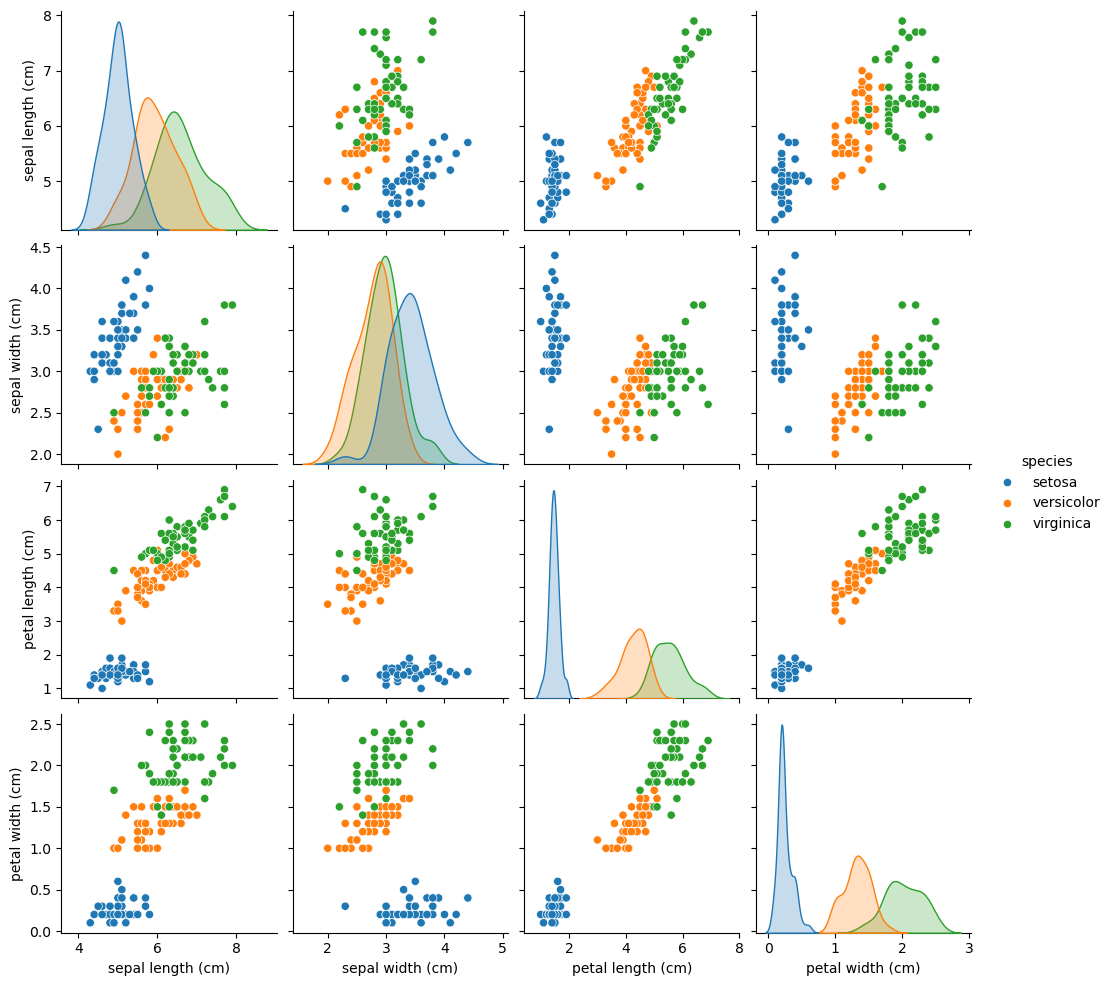
Box Plot
sns.boxplot(x='species', y='sepal length (cm)', data=iris_df)
plt.title('Sepal Length by Species')
plt.show()
# 세 가지 품종(setosa, versicolor, virginica)의 꽃받침 길이(sepal length)의 분포를 시각화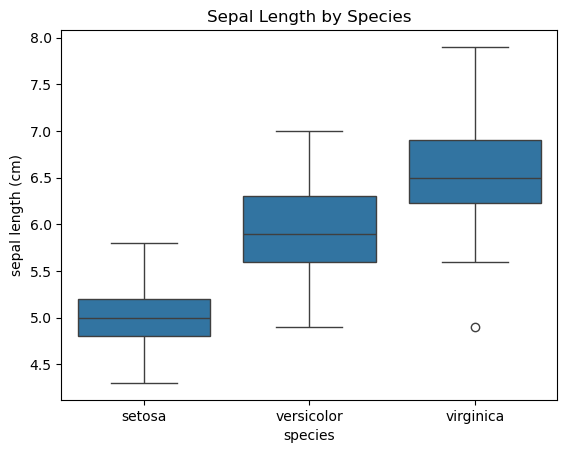
Heatmap
# 상관계수(correlation matrix) 계산
corr = iris_df.iloc[:, :-1].corr()
# 히트맵 시각화
sns.heatmap(corr, annot=True, cmap='coolwarm') # 각 셀에 상관계수 값을 표시 / 색상 팔레트를 ‘coolwarm’으로 설정
plt.title('Correlation Heatmap of Iris Features')
plt.show()
Violin Plot
# 데이터의 분포를 부드러운 곡선으로 나타내며, 박스플롯보다 더 많은 분포 정보를 제공
sns.violinplot(x='species', y='petal length (cm)', data=iris_df)
plt.title('Petal Length by Species')
plt.show()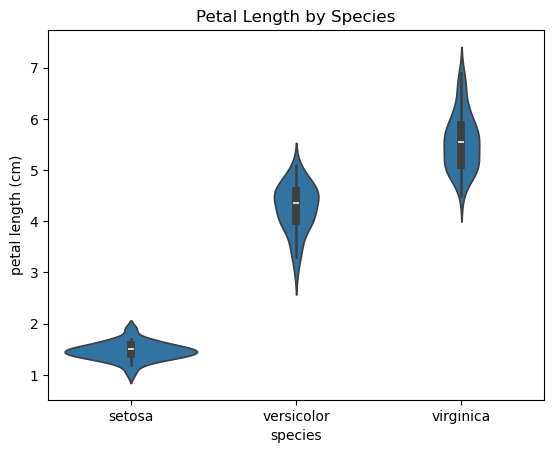
FacetGrid 활용
# FacetGrid를 활용하여 여러 개의 그래프를 한 번에 그릴 수 있음
g = sns.FacetGrid(iris_df, col="species")
g.map(plt.scatter, "sepal length (cm)", "sepal width (cm)") # species별로 sepal length와 sepal width의 관계를 나타낸 산점도
plt.show()
Regression Plot (선형 회귀 플롯)
sns.lmplot(x='sepal length (cm)', y='sepal width (cm)', hue='species', data=iris_df) # 품종별로 다른 색상과 회귀선을 적용
plt.title('Sepal Length vs Width with Regression Line')
plt.show()
'데이터 분석 부트캠프 > 주간학습일지' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 16기 9주차 - SQL 문법 (2) | 2024.10.18 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 16기 8주차 - SQL 기본 이론 (3) | 2024.10.11 |
| [패스트캠퍼스] 데이터 분석 부트캠프 16기 4주차 - Python의 Selenium을 활용한 데이터 크롤링 (6) | 2024.09.13 |
| [패스트캠퍼스] 데이터 분석 부트캠프 16기 3주차 - Python 제어문/예외처리/함수/변수/클래스 (7) | 2024.09.05 |
| [패스트캠퍼스] 데이터 분석 부트캠프 16기 3주차 - Python 자료형 (1) | 2024.09.03 |